
 |
 |
 |
|
|
|||
28.4 INTRODUCING CONCURRENT EXECUTIONWhat --- if not the notion of process --- fundamentally distinguishes concurrent from sequential computation? ProcessorsTo narrow down the specifics of concurrency, it is useful to take a new look at the figure which helped us lay the very foundations of the object-oriented approach by examining the three basic ingredients of computation:
To perform a computation is to use certain processors to apply certain actions to certain objects. At the beginning of this book we discovered how the object-oriented method addresses fundamental issues of reusability and extendibility by building software architectures in which actions are attached to objects (more precisely, object types) rather than the other way around. What about processors? Clearly we need a mechanism to execute the actions on the objects. But in sequential computation there is just one thread of control, hence just one processor; so it is taken for granted and remains implicit most of the time. In a concurrent context, however, we will have two or more processors. This property is of course essential to the idea of concurrency and we can take it as the definition of this notion. This is the basic answer to the question asked above: processors (not processes) will be the principal new concept for adding concurrency to the framework of sequential object-oriented computation. A concurrent system may have any number of processors, as opposed to just one for a sequential system. The nature of processors------------------------------------------------------------------------- Definition: processor A processor is an autonomous thread of control capable of supporting the sequential execution of instructions on one or more objects. ------------------------------------------------------------------------- This is an abstract notion, not to be confused with that of physical processing device, for which the rest of this chapter will use the term CPU, common in computer engineering to denote the processing units of computers. "CPU" is originally an abbreviation of "Central Processing Unit" even though there is most of the time nothing central about CPUs. Although we can use a CPU to implement a processor, the notion of processor is much more abstract and general. A processor can be, for example:
Threads are mini-processes. A true process can itself contain many threads, which it manages directly; the operating system (OS) only sees the process, not its threads. Usually the threads of a process will all share the same address space (in object-oriented terms, they potentially have access to the same set of objects), whereas each process has its own address space. We may view threads as coroutines within a process. The main advantage of threads is efficiency: whereas creating a process and synchronizing it with other processes are expensive operations, requiring direct OS intervention (to allocate the address space and the code of the process), the corresponding operations on threads are much simpler, do not involve any expensive OS operations, and so can be faster by a factor of several hundreds or even several thousands. The difference between processors and CPUs was clearly expressed by Henry Lieberman ([Lieberman 1987], page 22; square brackets signal differences in terminology and concurrency model): The number of [processors] need not be bounded in advance, and if there are too many [processors] for the number of real physical [CPUs] you have on your computer system, they are automatically time-shared. Thus the user can pretend that processor resources are practically infinite. To avoid any misunderstanding, be sure to remember that throughout this chapter the "processors" denote virtual threads of control; any reference to the physical units of computation uses the term CPU. At some point prior to execution, you will of course need to assign computational resources to the processors. The mapping will be expressed by a "Concurrency Control File" as described below. Handling an objectAny feature call must be handled (executed) by some processor. More generally, any object O2 is handled by a certain processor, its handler; the handler is responsible for executing all calls on O2 (all calls of the form x.f (a) where x is attached to O2). We may go further and specify that the handler is assigned to the object at the time of creation, and remains the same throughout the object's life. This assumption will help keep the mechanism simple. It may seem restrictive at first, since some distributed systems may need to support object migration across a network. But we can address this need in at least two other ways:
The dual semantics of callsWith multiple processors, we face a possible departure from the usual semantics of the fundamental operation of object-oriented computation, feature call, of one of the forms x.f (a) -- if f is a command y := x.f (a) -- if f is a query As before, let O2 be the object attached to x at the time of the call, and O1 the object on whose behalf the call is executed. (In other words, the instruction in either form is part of a call to a certain routine, whose execution uses O1 as its target.) We have grown accustomed to understanding the effect of the call as the execution of f's body applied to O2, using a as argument, and returning a result in the query case. If the call is part of a sequence of instructions, as with ... previous_instruction; x.f (a); next_instruction; ... (or the equivalent in the query case), the execution of next_instruction will not commence until after the completion of f. Not so any more with multiple processors. The very purpose of concurrent architectures is to enable the client computation to proceed without waiting for the supplier to have completed its job, if that job is handled by another processor. In the example of print controllers, sketched at the beginning of this chapter, a client application will want to send a print request (a "job") and continue immediately. So instead of one call semantics we now have two cases:
The asynchronous case is particularly interesting for a command, since the remainder of the computation may not need any of the effects of the call on O2 until much later (if at all: O1 may just be responsible for spawning one or more concurrent computations and then terminating.) For a query, we need the result, as in the above example where we assign it to y, but as explained below we might be able to proceed concurrently anyway. Separate entitiesA general rule of software construction is that a semantic difference should always be reflected by a difference in the software text. Otherwise the software is ambiguous. Now that we have two variants of call semantics we must make sure that the software text incontrovertibly indicates which one is intended in each case. What determines the answer is whether the call's target, O2, has the same handler (the same processor) as the call's originator, O1. So rather than the call itself we should mark x, the entity denoting the target object. In accordance with the static typing policy, developed in earlier chapters to favor clarity and safety, the mark should appear in the declaration of x. This reasoning will give the only notational extension supporting concurrency. Along with the usual x: SOME_TYPE we allow ourselves the declaration form x: separate SOME_TYPE to express that x may become attached to objects handled by a different processor. If a class is meant to be used only to declare separate entities, you can also declare it as separate class X ... The rest as usual ... instead of just class X ... or deferred class X .... The convention is the same as for declaring an expanded status: you can declare y as being of type expanded T, or equivalently just as T if T itself is a class declared as expanded class T.... It is quite remarkable that this addition of a single keyword suffices to turn our sequential object-oriented notation into one supporting general concurrent computation. Some straightforward terminology. We may apply the word "separate" to various elements, both static (appearing in the software text) and dynamic (existing at run time). Statically: a separate class is a class declared as separate class ...; a separate type is based on a separate class; a separate entity is declared of a separate type, or as separate T for some T; x.f (...) is a separate call if its target x is a separate entity. Dynamically: the value of a separate entity is a separate reference; if not void, it will be attached to an object handled by another processor --- a separate object. Typical examples of separate classes include:
Obtaining separate objectsIn practice, as illustrated by the preceding examples, there will be two kinds of separate object:
The separate object is said to be created in the first case and external in the second. To obtain a created object, you simply use the creation instruction. If x is a separate entity, the creation instruction create x.make (...) will, in addition to its usual effect of creating and initializing a new object, assign a new processor to handle that object. Such an instruction is called a separate creation. To obtain an existing external object, you will typically use an external routine, such as server (name: STRING; ... Other arguments ...): separate DATABASE where the arguments serve to identify the acquired object. Such a routine will typically send a message over the network and obtain in return a reference to the desired object. A word about possible implementations may be useful here to visualize the notion of separate object. Assume each of the processors is associated with a task (process) of an operating system such as Windows or Unix, with its own address space; this is of course just one of many concurrent architectures. Then one way to represent a separate object within a task is to use a small local object, known as a proxy:
The figure shows an object O1, instance of a class T with an attribute x: separate U. The corresponding reference field in O1 is conceptually attached to an object O2, handled by another processor. Internally, however, the reference leads to a proxy object, handled by the same processor as O1. The proxy, not directly visible to the concurrent application, contains enough information to identify O2: the task that serves as O2's handler, and O2's address within that task. All operations on x on behalf of O1 or other clients from the same task will go through the proxy. Any other processor that also handles objects containing separate references to O2 will have its own proxy for O2.
Be sure to note that this is only one possible technique, not a required property of the model. Operating system tasks with separate address spaces are just one way to implement processors. With threads, for example, the techniques may be different. Objects here, and objects thereWhen first presented with the notion of separate entity, some people complain that it is over-committing: "I do not want to know where the object resides! I just want to request the operation, x.f (...), and let the machinery do the rest --- execute f on x wherever x is." Although legitimate, this desire to avoid over-commitment does not obviate the need for separate declarations. As the quoted comment suggests, the precise location of an object is often an implementation detail that should not affect the software. But one boolean location property remains relevant: whether the object is handled by the same processor or by another. The answer determines a fundamental property: are calls on the object synchronous or asynchronous --- must we wait, or can we proceed? Ignoring this property in the software would not be a convenience: it would be a mistake. Once we know the object is separate, it should not in most cases matter for the functionality of our software (although it may matter for its performance) whether it belongs to another thread of the same process, another process on the same computer, another computer in the same room, another room in the same building, another site on the company's private network, or another Internet node half-way around the world. But it matters that it is separate. Mapping the processors: the Concurrency Control FileIf the software text does not need to specify the physical CPUs, this specification must appear somewhere else. Here is a way to take care of it. This is only one possible solution, not a fundamental part of the approach. We use a "Concurrency Control File" (CCF for short) which describes the concurrent computing resources available to our software. CCFs are similar in purpose and outlook to Ace files used to control system assembly. A typical CCF looks like this:
creation
local_nodes:
system
"pushkin" (2): "c:\system1\appl.exe";
"akhmatova" (4): "/home/users/syst1";
Current: "c:\system1\appl2.exe"
end
remote_nodes:
system
"lermontov": "c:\system1\appl.exe";
"tiuchev" (2): "/usr/bin/syst2"
end
end
external
Ingres_handler: "mandelstam" port 9000;
ATM_handler: "pasternak" port 8001
end
default
port: 8001; instance: 10
end
Defaults are available for all properties of interest, so that each of the three possible parts (creation, external, default) is optional, as well as the CCF as a whole. The creation part specifies what CPUs to use for separate creations (instructions of the form createI> x.make (...) for separate x). The example uses two CPU groups: local_nodes, presumably covering local machines, and remote_nodes. The software can select a CPU group through a call such as
set_cpu_group ("local_nodes")
directing subsequent separate creations to use the CPU group local_nodes until the next call to set_cpu_group. This procedure comes from a class CONCURRENCY providing facilities for controlling the mechanism; we will encounter a few more of its features below. The corresponding CCF entry specifies what CPUs to use for local_nodes: the first two objects will be created on machine pushkin, the next four on akhmatova, and the next ten on the current machine (the one which executes the creation instructions); after that the allocation scheme will repeat itself --- two objects on pushkin and so on. In the absence of a processor count, as with Current here, the value is taken from the instance entry in the default part (here 10) if present, and is 1 otherwise. The system used to create each instance is an executable specified in each entry, such as c:\system1\appl.exe for pushkin (obviously a machine running Windows or OS/2). The external part specifies where to look for existing external separate objects. The names of such objects, Ingres_handler and ATM_handler in the example, are abstract names which will be used in the software as arguments to the functions that establish a connection with such an object. For example with the server function as assumed earlier server (name: STRING; ... Other arguments ...): separate DATABASE a call of the form server ("Ingres_handler", ...) will yield a separate object denoting the Ingres database server. The CCF indicates that the corresponding object resides on machine mandelstam and is accessible on port 9000. In the absence of a port specification the value used is drawn from the defaults part or, barring that, a universal default. The CCF is separate from the software. You may compile a concurrent or distributed application without any reference to a specific hardware and network architecture; then at run time each separate component of the application will use its CCF to connect to other existing components (external parts) and to create new components (creation parts). This presentation of the CCF conventions has shown how we can map the abstract concepts of concurrent O-O computation --- processors, created separate objects, external separate objects --- to physical resources. As noted, these conventions are only an example of what can be done, and they are not part of the basic concurrency mechanism. But they demonstrate that it is possible to decouple the software architecture of a concurrent system from the concurrent hardware architecture available at any particular stage. Validity rules: unmasking traitorsBecause the semantics of calls is different for separate and non-separate objects, it is essential to guarantee that a non-separate entity (declared as x: T for non-separate T) can never become attached to a separate object. Otherwise a call x.f (a) would wrongly be understood --- by the compiler, among others --- as synchronous, whereas the attached object is in fact separate and requires asynchronous processing. Such a reference, falsely declared as non separate while having its loyalties on the other side, will be called a traitor. We need a simple validity rule (in three parts) to guarantee that our software has no traitor --- that every representative or lobbyist of a separate power is duly registered as such with the appropriate authorities. The first part of the rule avoids producing traitors through attachment, that is to say assignment or argument passing: ------------------------------------------------------------------- Separateness consistency rule (1) If the source of an attachment (assignment instruction or argument passing) is separate, its target entity must be separate too. ------------------------------------------------------------------- An attachment of target x and source y is either an assignment x := y or a call f (..., y, ...) where the actual argument corresponding to x is y. Having such an attachment with y separate but not x would make x a traitor, since we could use x to access a separate object (the object attached to y) under a non-separate name, as if it were a local object with synchronous call. The rule disallows this. Note that syntactically x is an entity but y may be any expression. This means that the rule assumes we have defined the notion of "separate expression", in line with previous definitions. A simple expression is an entity; more complex expressions are function calls (remember in particular that an infix expression such as a + b is formally considered a call, similar to something like a.plus (b)). So the definition is immediate: an expression is separate if it is either a separate entity or a separate call. As will be clear from the rest of the discussion, permitting an attachment of separate target and non-separate source is harmless --- although not very useful. We need a complementary rule covering the case in which a client passes to a separate supplier a reference to a local object. Assume the separate call x.f (a) where a, of type T, is not separate, although x is. The declaration of routine f, for the generating class of x, will be of the form f (u: ... SOME_TYPE) and the type T of a must conform to SOME_TYPE. But this is not sufficient! Viewed from the supplier's side (that is to say, from the handler of x), the object O1 attached to a has a different handler; so unless the corresponding formal argument a is declared as separate it would become a traitor, giving access to a separate object as if it were non-separate:
So SOME_TYPE must be separate; for example it may be separate T. Hence the second consistency rule: --------------------------------------------------------------------- Separateness consistency rule (2) If an actual argument of a separate call is of a reference type, the corresponding formal argument must be declared as separate. --------------------------------------------------------------------- The issue only arises for arguments of reference type. The other case, expanded types, including in particular the basic types such as INTEGER, is considered next. As an application of the technique, consider an object that spawns several separate objects, which will later be able to rely on its resources; it is saying to them, in effect, "Here is my business card; call me if you need to". A typical example would be an operating system's kernel that creates several separate objects and stands ready to perform operations for them later on. The creation calls will be of the form create subsystem.make (Current, ... Other arguments ...) where Current is the "business card" enabling subsystem to remember its progenitor, and ask for its help in case of need. Because Current is a reference, the corresponding formal argument in make must be declared as separate. Most likely, make will be of the form
make (p: separate PROGENITOR_TYPE; ... Other arguments ...) is
do
progenitor := p;
... Rest of subsystem initialization operations ...
end
keeping the value of the progenitor argument in an attribute progenitor of the enclosing class. The second separateness consistency rule requires p to be declared as separate; so the first rule requires the same of attribute progenitor. Later calls for progenitor resources, of the form progenitor.some_resource (...) will, correctly, be treated as separate calls. Since the second consistency rule only applies to actual arguments of reference types, we need one more rule for the other case, expanded types: ---------------------------------------------------------------------------- Separateness consistency rule (3) If an actual argument of a separate call is of an expanded type, its base class may not include, directly or indirectly, any attribute of a reference type. ---------------------------------------------------------------------------- In other words, the only expanded values that we can pass in a separate call are "completely expanded" objects, with no references to other objects. Otherwise we could again run into traitor trouble since attaching an expanded value implies copying an object:
The figure illustrates the case in which the formal argument u is itself expanded. Then the attachment is simply a copy of the fields of the object O1 onto those of the object O'1 attached to u. Permitting O1 to contain a reference would produce a traitor field in O'1. The problem would also arise if O1 had a subobject with a reference; hence the mention "directly or indirectly" in the rule.
If the formal argument u is a reference, the attachment is a clone; the call would create a new object O'1 similar to the above and attach reference u to it. In this case the solution is to create the clone explicitly on the client's side, before the call: a: expanded SOME_TYPE; a1: SOME_TYPE; ... a1 := a; -- This clones the object and attaches a1 to the clone. x.f (a1) As per the second validity rule, the formal argument u must be of a separate reference type, separate SOME_TYPE or conforming; the call on the last line makes u a separate reference attached to the newly created clone on the client's side. Importing object structuresA consequence of the separateness consistency rules is that it is not possible to use the clone function (from the universal class ANY) to obtain an object handled by another processor. The function is declared as
clone (other: GENERAL): like other is
-- New object, field-by-field identical to other
...
so that an attempt to use y := clone (x) for separate x would violate part 1 of the rule: x, which is separate, does not conform to other which is not. This is what we want: a separate object running on a machine in Vladivostok may contain (non-separate) references to objects that are in Vladivostok too; but then if you could clone it in Kansas City, the resulting object would contain traitors --- references to those objects, now separate, even though in the generating class the corresponding attributes are not declared as separate. The following function, also in class GENERAL, enables us to clone separate object structures without producing traitors:
deep_import (other: separate GENERAL): like other is
-- New object, field-by-field identical to other
...
The result is a non-separate object structure, recursively duplicated from the separate structure starting at other. For the reasons just explained, a shallow import operation could yield traitors; so what we need, and what deep_import provides, is the equivalent of deep_clone applied to a separate object. It will import the entire structure, making all the duplicated objects non-separate. (It may of course still contain separate references if the original structure contained references to objects handled by another processor.) For the developers of distributed systems, deep_import is a convenient and powerful mechanism, through which you can transfer possibly large object structures across a network without the need to write any specialized software, and with the guarantee that the exact structure (including cycles etc.) will be faithfully duplicated.
|
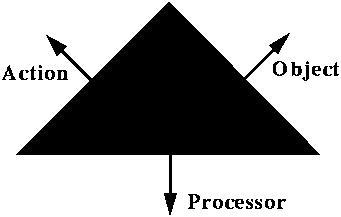
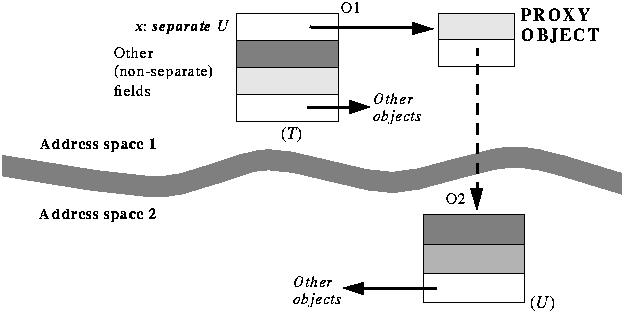
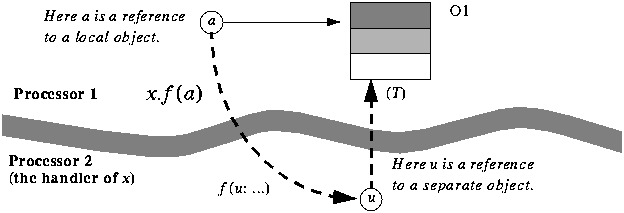
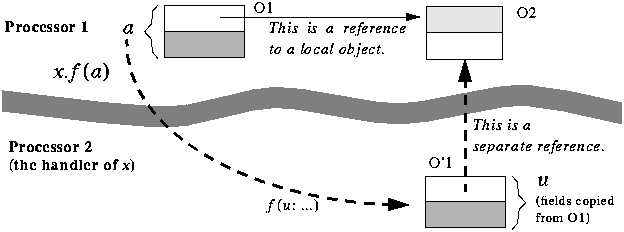

 Table of Contents
Table of Contents Next section
Next section