|
 |
 |
|
|
|||
25.11 HOW INHERITANCE STRUCTURES ARE PRODUCED
When you read a book or pedagogical articles on the object-oriented method, or when you discover a class library, the inheritance hierarchies that you see have already been designed, and the author does not always tell you how they got to be that way. How then do you go about designing your own structures? Specialization and abstractionVoluntarily or not, pedagogical presentations often create the impression that inheritance structures should be designed from the most general (the upper part) to the most specific (the leaves). This is in part because this is often the best way to describe a good structure once it exists: from the general to the particular; from the figures to the closed figures to the polygons to the rectangles to the squares. But the best way to describe a structure is not necessarily the best way to produce it. A similar comment, due to Michael Jackson,. was mentioned in the discussion of top-down design.
In an ideal world populated with perfect people, we would always recognize the proper abstractions right away, and then draw the categories, their subcategories and so on. In the real world, however, we often see a specific case before we discover the general abstraction of which it is but a variant. In many cases the abstraction is not unique; how best to generalize a certain notion depends on what you or your clients will most likely want to do with the notion and its variants. Consider for example a notion that we have often encountered in earlier discussion: points in a two-dimensional space. At least four generalizations are possible:
Although some of these generalizations may intuitively be more appealing than others, it is impossible to say in the absolute which one of them is the best. The answer will depend on how your software base evolves and what it will need. So a prudent process in which you sometimes abstract a bit too late, because you waited until you were sure that you had found the most useful path of generalization, may be preferable to one in which you might get too much untested abstraction too soon. The arbitrariness of classificationsThe POINT example is typical. When presented with two competing classifications of a certain set of abstractions, you will often be able to determine, based on rational arguments, which one is better; but seldom is one in a position to determine that a certain inheritance structure is the best possible one. This situation is not specific to software. Do not believe, for example that the Linnaean classifications of natural science are universally accepted or eternal. The maintainers of the "Tree of Life" Internet archive mentioned earlier (see also the bibliographical notes) state at the outset that the project's classification --- however collaborative and interdisciplinary --- is controversial. And this is not just for weird smallish creatures too viscous to be discussed at lunch; the classification of birds cited earlier comes with the comment
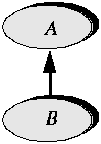
This shows the competition between two systems: the traditional one, based on morphology (and evolution); and a more inductive one, based on DNA analysis. They lead to radically different results. Also note, as an aside, that here we see a zoologist who does think that flightlessness should be a significant taxonomical criterion --- but the official classification disagrees. Induction and deductionTo design software hierarchies, the proper process is a combination of the deductive and the inductive, of specialization and generalization sometimes you see the abstraction first and then infer the special cases; sometimes you first build or find a useful class and then realize that there is a more abstract underlying concept. If you find yourself not always using the first scheme, but once in a while discovering the abstract only after you have seen the concrete, maybe there is nothing wrong with you. You are simply using a normal "yoyo" approach to classification. As you accumulate experience and insight, you should find that the share of (correct) a priori decisions grows. But an a posteriori component will always remain. In the natural sciences too, classifications are subject to constant reevaluation. One of the opening comments in the "Tree of Life" Internet archive mentioned earlier (and referenced in the bibliographical notes) is that classification is controversial. Varieties of class abstractionTwo forms of a posteriori parent construction are common and useful. Abstracting is the late recognition of a higher-level concept. You find a class B which covers a useful notion, but whose developer did not recognize that it was actually a special case of a more general notion A, justifying an inheritance link:
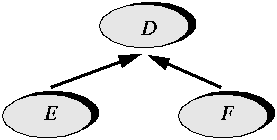
That this insight was initially missed --- that is to say, that B was build without A --- is not a reason to renounce the use of inheritance in this case. Once you recognize the need for A, you can, and in most cases should, write this class and adapt B to become one of its heirs. It is not as good as having written A earlier, but better than not writing it at all. Factoring is the case in which you detect that two classes E and F actually represent variants of the same general notion:
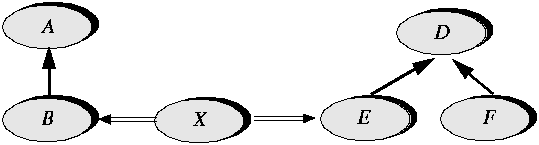
If you recognize this commonality belatedly, the generalization step will enable you to add a common parent class D. Here again it would have been preferable to get the hierarchy right the first time around, but late is better than never. Client independenceAbstracting and factoring may in many cases proceed without negative effects on the existing clients (an application of the open-closed principle). This property results from the method's use of information hiding. Consider again the preceding schematic cases, but with a typical client class now added to the picture:
When B gets abstracted into A, or the features of E get factored with those of F into D, a class X that is a client of B or E (on the picture it is a client of both) will in many cases not feel any effect from the change. The ancestry of a class does not affect its clients if they are simply applying the features of the class on entities of the corresponding type. In other words, if X uses B and E as suppliers under the scheme b1: B ; e1: E; ... b1lsome_feature_of_B; ... e1lsome_feature_of_E then X is unaffected by any re-parenting of B or E arising from abstracting or factoring. Elevating the level of abstractionAbstracting and factoring are typical of the process of continuous improvement that characterizes a successful object-oriented software construction process. In my experience this is one of the most exciting aspects of practicing the method: knowing that even though you are not expected to reach perfection the first time around, you are given the opportunity to improve your design continually, until it satisfies everyone. In a development group that applies the method
well, this regular elevation of the level of abstraction of the
software, and as a corollary of its quality, is clearly perceptible to the
project members, and serves as constant incentive and motivation.
PREVIOUS SECTION ---- NEXT SECTION
|