
 |
 |
 |
|
|
|||
28.6 ACCESSING SEPARATE OBJECTSWe now have enough background to devise the proper synchronization mechanisms for our concurrent object-oriented systems. Concurrent accesses to an objectThe first question to address is how many executions may proceed concurrently on an object. The answer was in fact implicit in the definition of the notions of processor and handler: if all calls to features on an object are executed by its handler (the processor in charge of it), and a processor is a single thread of execution, it follows that at most one feature may be executing on a given object at any time. Should we not allow several routines to execute concurrently on a given object? The main incentive for answering no is to retain the ability to reason on our software. The study of class correctness in an earlier chapter provides the proper perspective. We saw the life cycle of an object pictured as this:
In this view the object is externally observable only in the states marked as shaded squares: just after creation (S1), after every application of a feature by a client (S2 and subsequent states). These have been called the "stable times" of the object's life. A consequence was the formal rule: to prove the correctness of the class, we only have to verify one property for each creation procedure, and one property for each exported feature. If p is a creation procedure, the property to check is
{Default and prep} Bodyp {postp and INV}
meaning: if you execute the body of p when the object has been initialized to the default values and the precondition of p holds, you will end up satisfying the postcondition and the invariant. For an exported routine r, the property to check is
{prer and INV} Bodyr {postr and INV}
meaning: if you execute r when the precondition and the invariant are satisfied, you will end up satisfying the postcondition and the invariant. So the number of things to check is very limited; there are no complicated run-time scenarios to analyze. This is important even in a somewhat informal approach to software development, which still requires the ability to reason about the software execution by looking at the software text. The informal version of the preceding properties is that you can understand the class by looking at its routines separately from each other --- convincing yourself, however informally, that each of them will deliver the intended final state starting from the expected initial state. Introduce concurrent execution into this simple, consistent world, and all hell breaks loose. Even plain interleaving, in which we would start executing a routine, interrupt it in favor of another, switch back to the first and so on, would deprive us from any ability to use straightforward reasoning on our software texts. We simply would not have any clue as to what can happen at run-time; trying to follow would force us to examine all possible interleavings, immediately leading to a combinatorial explosion of cases to consider. So for simplicity and consistency we will let at most one routine execute on any particular object at any particular time. Note, however, that in a case of emergency, or if a client keeps an object for too long, we should be able to interrupt the client, as long as we do so in a sufficiently violent way --- triggering an exception --- to ensure that the unfortunate client will receive a notification, enabling it to take corrective action if appropriate. The mechanism of duels, explained later, offers that possibility. Reserving an objectWe need a way for a client to obtain exclusive access to a certain resource, represented by a certain object. An idea which seem attractive at first (but will not suffice) would be simply to rely on the notion of separate call. Consider, executed on behalf of a certain client object O1, the call x.f (...), for separate x attached at run time to O2. Once the call has started executing, we have seen that O1 can safely move to its next business without waiting for the call's termination; but this execution of the call cannot start until O2 is free for O1. So we might decide that before starting the call the client will wait until the target object is free. Unfortunately this simple scheme is not sufficient, because it does not allow the client to decide how long to retain an object. Assume O2 is some shared data structure such as a buffer, and the corresponding class provides procedure remove to remove an element. A client O1 may need to remove two consecutive elements, but just writing buffer.remove; buffer.remove will not do: between the two instructions, any other client can jump in and perform operations on the shared structure! So the two elements might not be adjacent. One solution is to add to the generating class of buffer (or of a descendant) a procedure remove_two that removes two elements at once. But in the general case that is unrealistic: you cannot change your suppliers for every synchronization need of your own client code. There must be a way for the client to reserve a supplier object for as long as it needs it. In other words, we need something like a critical region mechanism. The syntax introduced earlier ("Synchronization- based mechanisms", page 948) was hold a then actions_requiring_exclusive_access end or the conditional variant hold a when a.some_property then actions_requiring_exclusive_access end We will, however, go for a simpler approach, perhaps surprising at first. The convention will simply be that any call using a separate expression a as argument will wait at run time (if a is not void) until the attached object is available. In other words, there is no need for the hold instruction; the effect will simply be achieved through the call actions_requiring_exclusive_access (a) where a is separate, and the procedure takes an argument. (The final form of this rule also involves preconditions, and so will be given in full later in this chapter, on page 966.) Other policies are possible, and indeed some authors have proposed retaining a hold instruction (see the bibliographical notes). But the use of argument passing as the object reservation mechanism helps keep the concurrency model simple and easy to learn. One of the observations justifying this policy is that with the hold scheme shown above it will be tempting for developers, as part of the general "Encapsulate the Repetitive" theme of object-oriented development, to gather in a routine the actions that require exclusive access to an object; this trend was foreseen in the above summary of the hold instruction, where the actions appear as a single routine actions_requiring_exclusive_access. But then such a routine will need an argument representing the object; here we go further and consider that presence of such argument suffices to achieve the object reservation. This convention also means that, paradoxically enough, most separate calls do not need to wait. When we are executing the body of a routine that has a separate formal argument a, we know that we have already reserved the attached object, so any call with target a can proceed immediately. As we have seen, there is no need to wait for the call to terminate. In the general case, with a routine of the form
r (a: separate SOME_TYPE) is
do
...; a.r1 (...); ...
...; a.r2 (...); ...
end
an implementation can continue executing the intermediate instructions without waiting for any of the calls to terminate, as long as it logs all the calls on a so that they will be executed in the order requested. (We have yet to see how to wait for a separate call to terminate if that is what we want; so far, we just start calls and never wait!) If a routine has two or more separate arguments, a client call will wait until it can reserve all the corresponding objects. This requirement is hard on the implementation, which will have to use protocols for multiple simultaneous reservation; for that reason, an implementation might at first impose the restriction that a routine may have at most one separate formal argument. But if the full mechanism is implemented it provides considerable benefits to application developers; as a typical example, studied later in this chapter, the famous "dining philosophers" problem admits an almost trivial solution. Accessing separate objectsThe last example shows how to use, as the target of a separate call, a formal argument, itself separate, of the enclosing routine r. An advantage is that we do not need to worry about how to get access to the target object: this was taken care of by the call to r, which had to reserve the object --- waiting if necessary until it is free. We can go further and make this scheme the only one for separate calls: -------------------------------------------------------------------------- Separate Call rule The target of a separate call must be a formal argument of the routine in which the call appears. -------------------------------------------------------------------------- Remember that a call a.r (...) is separate if the target a is itself an entity or expression declared as separate. So if we have a separate entity a we cannot call a feature on it unless a is a formal argument of the enclosing routine. If, for example, attrib is an attribute declared as separate, we must use, instead of attrib.r (...), the call rf (attrib, ...) with
rf (x: separate SOME_TYPE; ... Other arguments ...) is
-- Call r on x.
do
x.r (...)
end
This rule may appear to place an undue burden on developers of concurrent applications, since it forces them to encapsulate all uses of separate objects in routines. It may indeed be possible to devise a variant of this chapter's model which does not include the Separate Call rule; but as you start using the model you will, I think, realize that the rule is in fact of great help. It encourages developers to identify accesses to separate objects and separate them from the rest of the computation. Most importantly, it avoids grave errors that would be almost bound to happen without it. The following case is typical. Assume a shared data structure --- such as, once again, a buffer --- with features remove to remove an element and count to query the number of elements. Then it is quite "natural" to write if buffer.count >= 2 then buffer.remove; buffer.remove end The intent is presumably to remove two elements. But, as we have already seen, this will not always work --- at least not unless we have secured exclusive access to buffer. Otherwise between the time you test count and the time you execute the first remove, any other client can come in and remove an element, so that you will end up trying to apply remove to an empty structure. Another example, assuming that we follow the style of previous chapters and include a feature item, side-effect-free, to return the element that remove removes, is if not buffer.empty then value := buffer.item; buffer.remove end Without a protection on buffer, another client may add or remove an element between the calls to item and remove. If the author of the above extract thinks that the effect is to access an element and remove it, he will be right some of the time; but if this is not your lucky day you will access an element and remove another --- so that you may for example (if you repeat the above scheme) access the same element twice! Very wrong. By making buffer an argument of the enclosing routine, we avoid these problems: buffer is guaranteed to be reserved for the duration of the routine's call. Of course the fault in the examples cited lies with the developer, who was not careful enough. But without the Separate Call rule such errors are too easy to make. What makes things really bad is that the run-time behavior is non-deterministic, since it depends on the relative speed of the clients. The bug will be intermittent, here one minute, gone the next. Worse yet, it will probably occur rarely: after all (using the first example) a competing client has to be quite lucky to squeeze in between your test of count and your first call to remove. So the bug may be very hard to reproduce and isolate. Such tricky bugs are responsible for the nightmarish reputation of concurrent system debugging. Any rule that can significantly decrease their likelihood of occurring is a big potential help. With the Separate Call rule you will write the examples as the following procedures, assuming a separate type BOUNDED_BUFFER detailed below:
remove_two (buffer: BOUNDED_BUFFER) is
-- Remove the oldest two elements.
do
if buffer.count >= 2 then
buffer.remove; buffer.remove
end
end
get_and_remove (buffer: BOUNDED_BUFFER) is
-- Assign oldest element to value, and remove it.
do
if not buffer.empty then
value := buffer.item; buffer.remove
end
end
The routines may be part of some application class; preferably, they will appear in a class BUFFER_ACCESS which encapsulate buffer manipulation operations, and serves as parent to application classes needing to use buffers of the appropriate type. The example procedures both seem to be crying for a precondition. We will shortly see to it that they can get it. Wait by necessityAssume that a separate call such as buffer.remove has been started, after waiting if necessary for any separate arguments to become available. We have seen that from then on it does not block the client, which can proceed with the rest of its computation. But surely the client may need to resynchronize with the supplier. When should we wait for the call to terminate? It would seem that we need a special mechanism, as has indeed been proposed by some concurrent O-O languages such as Hybrid, to reunite the parent computation with its prodigal call. But instead we can use the idea of wait by necessity, due to Denis Caromel. The goal is to wait when we truly need to, but no earlier. When does the client need to be sure that a call a.r (...), for separate a, is finished? Not when it is doing something else on other objects, separate or not; not even necessarily when it has started a new procedure call a.r (...) on the same separate object since, as we have seen, a smart implementation can simply log such calls so that they will be processed in the order emitted (an essential requirement, of course); but when we need to access some property of the object. Then we require the object to be available, and all preceding calls on it to have been finished. You will remember the division of features into commands (procedures), which perform some transformation on the target object, and queries (functions and attributes) which return information about it. Command calls do not need to wait, but query calls may. Consider for example a separate stack s and the successive calls s.put (x1); .. Other instructions ...; s.put (x2); ... Other instructions ...; value := s.item (which because of the Separate Call rule must appear in a routine of which s is a formal argument). Assuming none of the Other instructions uses s, the only one that requires us to wait is the last instruction since it needs some information about the stack, its top value (which in this case should be x2). These observations yield the basic concept of wait by necessity: once a separate call has started, a client only needs to wait for its termination if the call is to a query. A more precise rule will be given below, after we look at a practical example. Wait by necessity (also called "lazy wait", and similar to mechanisms of "call by necessity" and "lazy evaluation" familiar to Lispers and students of theoretical computing science) is a convenient rule which enables you to start parallel computations as you need and avoid unnecessary waiting, but be reassured that the computation will wait when it needs to. A multi-launcherHere is a typical example showing the need for wait by necessity. Assume that a certain object must create a set of other objects, each of which goes off on its own:
launch (a: ARRAY [separate X]) is
-- Get every element of a started.
require
-- No element of a is void
local
i: INTEGER
do
from i := a.lower until i > a.upper loop
launch_one (a @ i); i := i + 1
end
end
launch_one (p: separate X) is
-- Get p started.
require
p /= Void
do
p.live
end
If, as may well be the case, procedure live of class X describes an infinite process, this scheme relies on the guarantee that each loop iteration will proceed immediately after starting launch_one, without waiting for the call to terminate: otherwise the loop would never get beyond its first iteration. One of the examples below uses this scheme. An optimization(This section examines a fine point and may be skipped on first reading.) To wrap up this discussion of wait by necessity we need to examine more carefully when a client should wait for a separate call to terminate. We have seen that only query calls should cause waiting. But we may go further by examining whether the query's result type is expanded or reference. (For the s.item example, assuming s of type STACK [SOME_TYPE], this is determined by SOME_TYPE.) If the type is expanded, for example if it is INTEGER or another of the basic types, there is no choice: we need the value, so the client computation must wait until the query has computed its result. But for a reference type, one can imagine that a smart implementation could still proceed while the result, a separate object, is being computed; in particular, if the implementation uses proxies for separate objects, the proxy object itself can be created immediately, so that the reference to it is available even if the proxy does not yet refer to the desired separate object. This optimization, however, complicates the concurrency mechanism because it means proxies must have a "ready or not" boolean attribute, and all operations on separate references must wait until the proxy is ready. It also seems to prescribe a particular implementation --- through proxies. So we will not retain it as part of the basic rule: --------------------------------------------------------------------------------- Wait by necessity If a client has started one or more calls on a certain separate object, and it executes on that object a call to a query, that call will only proceed after all the earlier ones have been completed, and any further client operations will wait for the query call to terminate. --------------------------------------------------------------------------------- To account for the possible optimization just discussed, replace "a call to a query" by "a call to a query returning of expanded type". Avoiding deadlockAlong with several typical and important examples of passing separate references to separate calls, we have seen that it is also possible to pass non-separate references, as long as the corresponding formal arguments are declared as formal (since, on the supplier's side, they represent foreign objects, and we do not want any traitors). Non-separate references raise a risk of deadlock and must be handled carefully. The normal way of passing non-separate references is what we have called the business card scheme: we use a separate call of the form x.f (a) where x is separate but a is not; that is to say, a is a reference to a local object of the client, possibly Current itself; on the supplier side, f is of the form
f (u: separate SOME_TYPE) is
do
local_reference := u
end
where local_reference, also of type separate SOME_TYPE, is an attribute of the enclosing supplier class. Later on, in routines other than f, the supplier may use local_reference to access objects on the original client's side. This scheme is sound. Assume, however, that f did more, for example that it included a call of the form u.g (...) for some g. This is likely to produce deadlock: the client (the handler for the object attached to u and a) is busy executing f or, with wait by necessity, may be executing another call that has reserved the same object. The following rule will avoid this kind of situation: -------------------------------------------------------------------------------- Business Card principle If a separate call uses a non-separate actual argument of a reference type, the routine should only use the corresponding formal as source of assignments. -------------------------------------------------------------------------------- At the present stage this is a only methodological guideline although it may be desirable to introduce a formal validity rule (exercise 28.4 asks you to explore this idea further.) Some more comments on deadlocks appear in the discussion section.
|
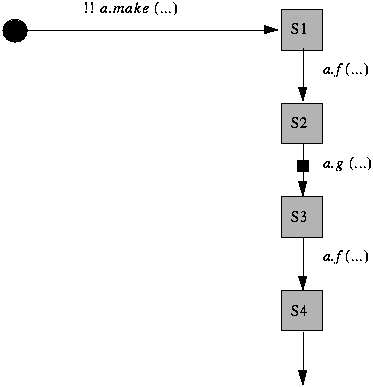
 Table of Contents
Table of Contents Next section
Next section